|
Rafał Adamczak Krzysztof Grąbczewski Karol Grudziński Norbert Jankowski Antoine Naud |
 |
|
Rafał Adamczak Krzysztof Grąbczewski Karol Grudziński Norbert Jankowski Antoine Naud |
|

What is this tutorial about:
Neural networks are universal approximators/classifiers (see textbooks for references)
... but are they good tools for real applications?
More methods of classification than datasets to classify.
Computational intelligence (CI) methods developed by experts in:

What type of explanation is satisfactory?
Interesting cognitive psychology (CS) problem.
Exemplar and prototype theories of categorization in CS:
Both are true, logical rules are the highest form of summarization.
Types of explanation:
Best explanation - depending on particular field.
Other implications of knowledge extraction:
Use of various forms of knowledge in one system is still rare.
Cf. DISCERN - distributed lexicon, NLP dialog system (Mikkulleinen)
Logical rules, if simple enough, are preferred by humans.

Are rules indeed the only way to understand the data?
Types of logical rules:
| small(x) | = True{x|x<1} |
| medium(x) | = True{x|x Î [1,2]} |
| large(x) | = True{x|x>2} |
Linguistic variables are used in crisp (propositional, Boolean) rules:
IF small-height(X) AND has-hat(X) AND has-beard(X) THEN (X is a Brownie)

ELSE IF ... ELSE ...
Crisp logic based on rectangular membership functions: True/False values jump from 0 to 1.
Step functions are used for partitioning of the input space.
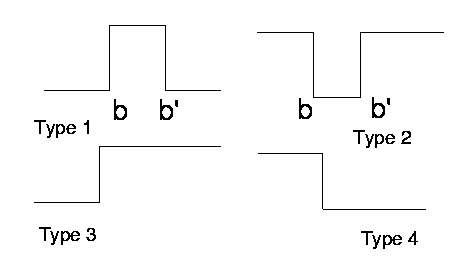
Decision regions: hyperrectangular (cuboidal).
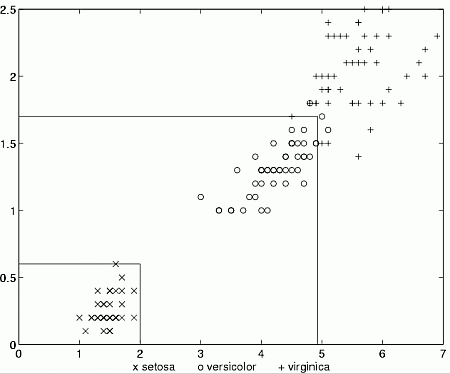
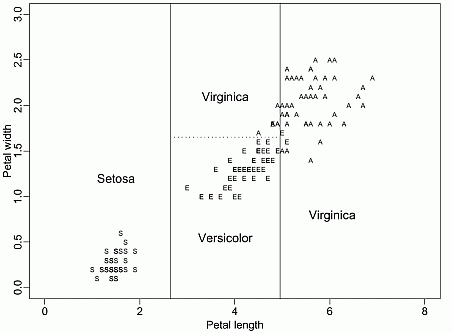
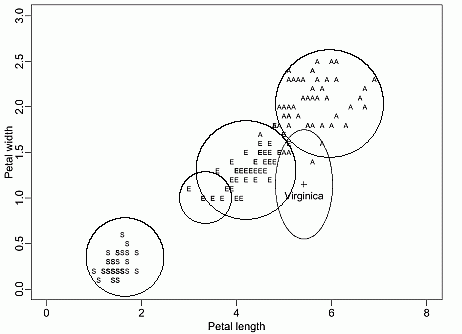
For example, some rules for the Iris data are:
| Setosa | PL <2 AND PW < 0.6 |
| Virginica | PL > 4.9 OR PW > 1.6 |
| Versicolor | ELSE |
Here are decision regions for these rules.
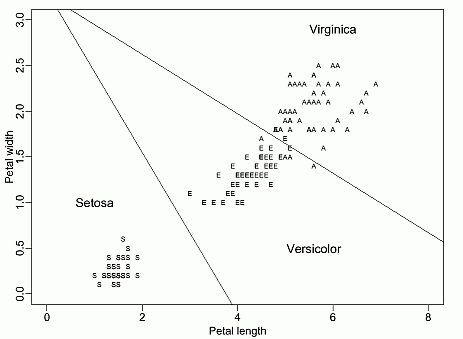
Decision trees provide crisp rules applied in a specific order.
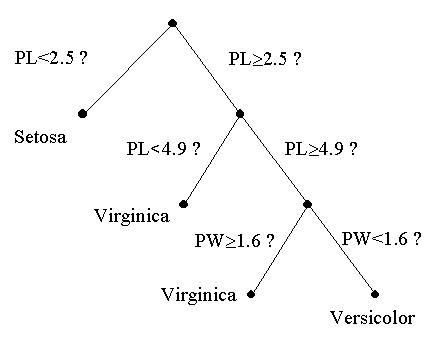
Here is a decision tree for Iris data.
Below its decision regions.
If hyperrectangular regions are too simple, rules are not accurate;
Solution: allow linear combinations of some inputs x.
Oblong decision trees, LDA, Linear Discrimination Analysis.
For example, a good rule for Iris is:
IF (SL+1.57SW-3.57PL-3.56PW<12.63) THEN Iris-versicolor
The number of problems that one may analyze using crisp logic may be limited.
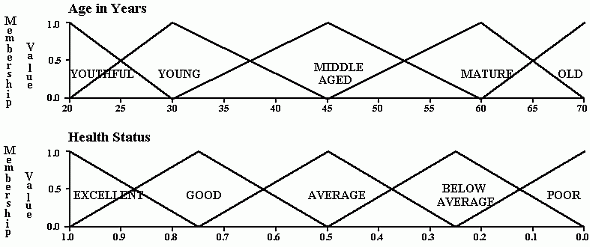
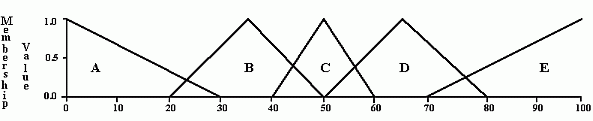
Typical approach: define triangular, trapezoidal, Gaussian and other type of membership functions.
Membership function m(x) - degree of truth that x has the property m
Instead of 0, 1 predicate function map into [0,1] interval.
Partition every feature into some membership functions, for example triangular.
Fuzzy logic: separable functions - products of one-dimensional factors:
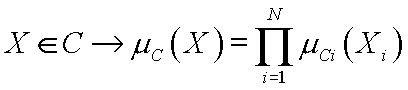
Many other possibilities exist to produce N-dimensional membership functions.
One form of fuzzy rules is:

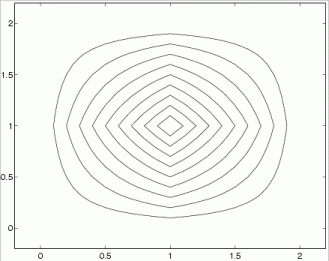
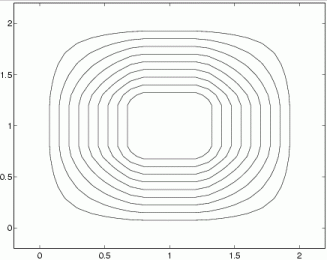
Triangular and trapezoidal membership functions give such countours in 2D for different Th
Rough set logic
Roughly: trapezoidal shapes of membership functions, but borders may be non-linear.
At least M conditions out of N are true.
Natural for neural systems, for example, if at least 2 logical conditions out of 4 are true:
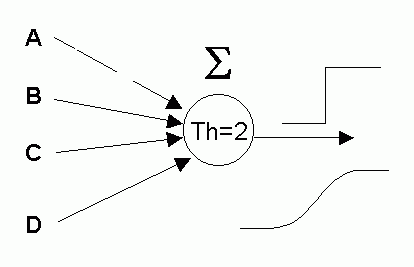
IF at least 2 conditions out of {A,B,C,D} are true
THEN (X is a Brownie)
ELSE IF ... ELSE ...
|
Clusters may have complex decision border shapes. IF (XÎC) THEN Factk = TRUE Granulation: covering with simpler shapes, corresponding to many rules.
Simple rules - non-linear feature transformations may be required.
|
|
Crisp logic rules are most desirable; try them first,
but remember ...

Fuzzy rules have continuous membership functions, giving some advantages:
But remember ...
 danger of overparameterization - more complex rules, additional position/shape parameters.
danger of overparameterization - more complex rules, additional position/shape parameters.

Problems with rule-based classification models:
Knowledge accessible to humans:
P-rules have the form:

D(X, P) is a distance function determining decision borders.
P-rules are easy to interpret!
IF X=You are most similar to the P=Superman THAN You are in the Super-league.
IF X=You are most similar to the P=Weakling THAN You are in the Failed-league.
In both cases “similar” may involve different features, i.e. different D(X, P) functions.
P-rules are more general than F-rules!
F-rules (and crisp rules) are P-rules with separable distance function.
If
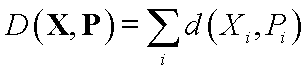
for example, Manhattan function, then:
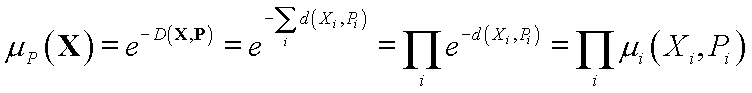
If d(Xi, Pi) = 1 for Xi Î [Pi - D Pi , Pi + D Pi], and 0 outside, crisp rules are obtained.
Example: P-rules for Iris.
First rule extraction/application is considered;
than some remarks on prototype-based and visualization-based methods are made.

Methodology of rule extraction, not a particular method.
Many decisions depend on particular application, not completely automatic.
Start from crisp rules - maybe they are sufficient?
Regularization of classification models (for example, network or tree pruning)
allows to explore simplicity-accuracy tradeoff.
A set of rules M is obtained.
Next step: optimization of rules exploring the confidence-rejection rate tradeoff.
Define confusion matrix F(Ci,Cj|M) counting the number of cases from class Cj assigned by the set of rules M to the class Ci.
For 2 class problems:
| F(Ci,Cj|M) = |
|
where Fij is the frequency of cases Nij/N.
F(Ci,Cj|R) may be defined for a rule or a class.
Sensitivity of rules: Se=F++ / (F+++F+-)
Î[0,1].
If Se=1 than all - cases (for example, sick) are never assigned to + class (for example, healthy).
Specificity of rules: Sp=F-- / (F-- + F-+)
Î[0,1].
If Sp=1 than the rule never assigns healthy to sick.
These combinations are sometimes maximized (especially in medical statistics).
Rule confidence factor (relative frequency):
Rc=F(Ci,Ci|R) /
Sj F(Ci,Cj|R).
Rule support: how many cases does a rule cover?
Various ways of rule evaluation: entropy (information), m-relative frequency and other
Ideal: only the diagonal confusion matrix elements summing to N should be left.
Define weighted combination of the number of errors and the "predictive power" of rules:
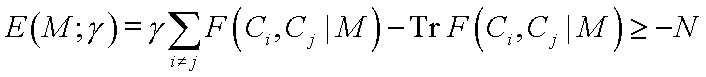
This should be minimized without constraints; it is bound by -N (number of all training vectors).
Sets of rules M are parameterized by Xk, X'k intervals.
For g=0 predictive power of rules is maximized.
Rules that make fewer errors on the training data should be more reliable.
Cost function E(M; g) allows to reduce the number of errors to zero (large g) for rules M that reject some instances.
Optional risk matrix may be used:
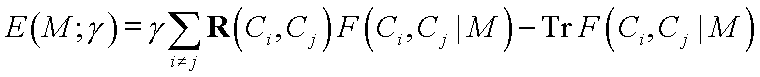
Optimization of rules for a single class or linguistic variables for a single rule is possible.
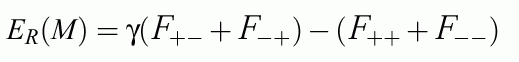
Note: if the confusion matrix F(Ci,Cj|M) is discontinuous non-gradient minimization methods should be used (simplex, simulated annealing etc).
Result: sets of rules Mk of different reliability.
Frequently more accurate rule R(1) is contained in the less accurate rule R(2)
Reliability should be calculated for the border R(2) - R(1) only.
Estimations of reliability may be poor.
Example: Iris hierarchical rules
Data from measurements/observations are not precise.
Finite resolution: Gaussian error distribution:
x => Gx=G(y;x,sx), where Gx is a Gaussian (fuzzy) number.
Given a set of logical rules {Â} apply them to input data {Gx }.
Use Monte Carlo sampling to recover p(Ci | X; {Â
}) - this may be used with any classifier.
Analytical estimation of this probability is based on cumulant function:
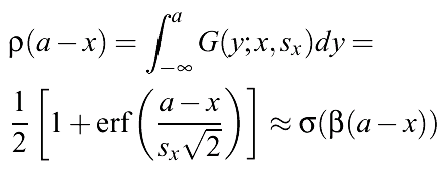
Approximation better than 2% for 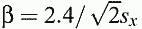
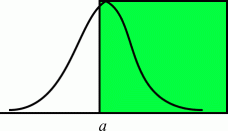
The rule Ra(x) = {x>a} is true for Gx with probability:
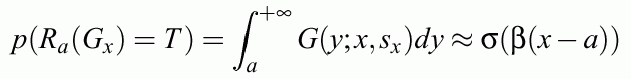
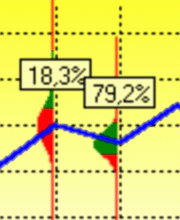
If the logistic function is used instead of the error function the exact error distribution is
s(x)(1-s(x)); for s2=1.7 it is within 3.5% identical with Gauss.
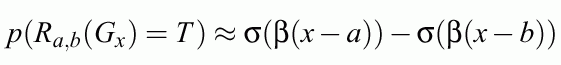
Soft trapezoidal membership functions realized by L-units are obtained.
Fuzzy logic with such membership functions and crisp inputs is equivalent to crisp logic with Gx;
this is realized by MLP neural networks with logistic transfer functions.
MLP < = > FL with trapezoidal membership functions.
For conjunctive rule with many independent conditions:
R = r1 Ů r2 Ů ...
rN
the probability p(Ci |X) is a product of
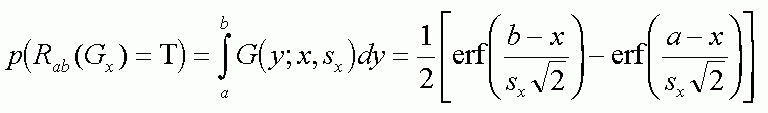
If several rules cover the same input region: adding probabilities counts the overlapping regions many times. For two rules created for class C:
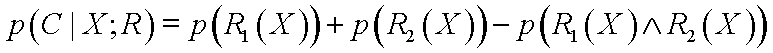
This formula simply avoids counting the same regions twice. For more than 2 rules overlapping more terms appear!
This is not a fuzzy approach!
Here small receptive fields are used, in fuzzy approach typically 2-5 large receptive fields define linguistic variables.
Benefits:
Alternative approaches: flexible matching in machine learning.
Several practical rule-extraction methods developed in our group:

Simplify the network leaving only 0, ±1 weights, use special linguistic units for input discretization.
Use integer weights/biases.
Start from Wij = 0, biasi = -0.5, change by 1.
Use beam search techniques instead of backpropagation.
FSM (Feature Space Mapping) - separable transfer functions, neurofuzzy network.
Crisp rules: FSM + rectangular transfer functions.
Fuzzy rules: FSM + context-dependent fuzzy membership functions.
Localized functions may be treated as prototypes.
SSV separability criterion: separate maximum number of pairs from different classes minimizing the number of separated pairs from the same class.
Select the best prototypes - "supermans".
Simplest approach: select references in k-nearest neighbor method.

Explanatory data analysis - show the data.
Overview of visualization methods: if time permits ...
SOM - most popular, trying to classify/display at the same time, but poorly.
May be used with any classifier.
Shows the probabilities in the neighborhood of the case analyzed for all/each feature.
Allows to evaluate reliability of classification, but not to explain the data.
Used directly on the data.
Shows interactively the neighborhood of the case analyzed preserving topographic relations.
Just a brief mention of GhostMiner, our data mining system developed in collaboration with Fujitsu Kyushu Ltd (FQS).
Results for many datasets illustrating the methodology described above.
Showing an example of a system based on rules derived from the data.
In real world projects training and finding optimal networks is not our hardest problem ...
Good methods to discover rules exist although proving that simplest sets of rules have been discovered is usually not possible.
Discovering hierarchical structure in the data:
Dealing with unknown values.
Constructing new, more useful features, from hundreds of 'weak' features.
Constructing the simplest explanations for the data.
Constructing theories that allow to reason about data.
Constructing new and modifying existing classes.
Building complex systems interacting with humans.
IEEE Transactions on Neural Networks 12 (2001) 277-306
Most papers are available from these pages
https://www.fizyka.umk.pl/kmk/publications.html
https://www.is.umk.pl/~duch/cv/papall.html


{kind=link}
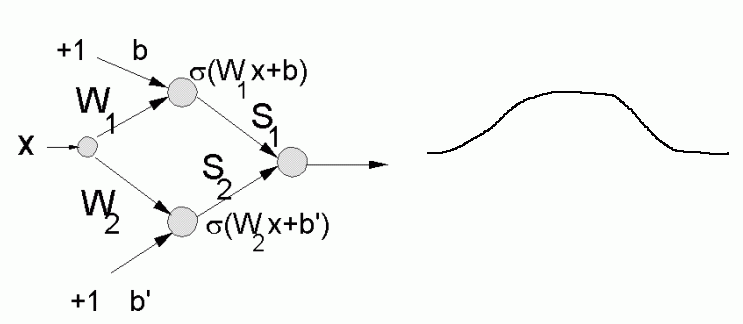{kind=link}