The trouble with doing something right the first time
is that nobody appreciates how difficult it was.
Anonymous
Review and comparison of many rule extraction methods:
R. Andrews, J. Diederich, A.B. Tickle, "A Survey and Critique of Techniques for Extracting Rules from Trained Artificial Neural Networks," Knowledge-Based Systems vol. 8, pp. 373-389, 1995.
Neural rule extraction algorithms differ in:
Early papers:
K. Saito, R. Nakano, "Medical diagnostic expert system based on PDP model",
Proc. of IEEE Int. Conf. on Neural Networks (San Diego CA), Vol 1 (1988) 255-262
Restrictions on the form of rules, the maximum number of positive and negative conditions, the depth of the breadth-first search process, including only conditions that were present in the training set.
KT algorithm: L.M. Fu, "Neural networks in computer intelligence", McGraw Hill, New York, 1994
Local method, conjunctive rules, depth of search is restricted.
Network weights help to limit the search tree.
G. Towell, J. Shavlik, "Extracting refined rules from knowledge-based neural networks". Machine Learning 13 (1993) 71-101
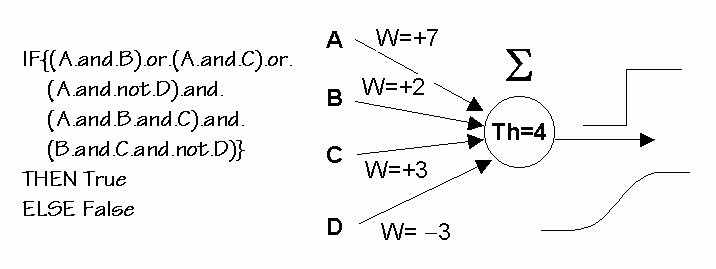
Analyze incoming weights of hidden and output neurons.
Consider all possible subsets of incoming weights Wi, positive or negative.
Find all combinations > Th
Example:
Problem: number of subsets is 2Ninp.
Exponentially growing number of possible conjunctive propositional rules.
Partial solution: restrict the number of antecedents, subsets or rules using some heuristics.
inputs with largest weights are analyzed first, combinations of two largest weights follow, until the maximum number of antecedent conditions is reached.
C. McMillan, M.C. Mozer, P. Smolensky, "Rule induction through integrated symbolic and subsymbolic processing".
In: J. Moody, S. Hanson, R. Lippmann, eds, Advances in NIPS 4,
Morgan Kaufmann, San Mateo, CA 1992
J.A. Alexander, M.C. Mozer,
"Template-based algorithms for connectionist rule extraction".
In: G. Tesauro, D. Touretzky, T. Leen, eds,
Advances in NIPS 7, MIT Press, Cambridge, MA, 1995
Used to find M of N rules and propositional rules.
Make hypothesis and test them - training algorithm, called “The Connectionist Science Game”, consists of 3-steps:
RulNet: 3 layer network, input, condition units and output action units.
Use weight templates exploring large spaces of candidate rules.
Only discrete-valued features, specific architecture for string-to-string mapping, for example character strings, not a general technique.
G. Towell, J. Shavlik, "Extracting refined rules from knowledge-based neural networks". Machine Learning 13 (1993) 71-101
Rules of the form:
IF M of N antecedents are true THAN ....
Sometimes more compact and comprehensible than conjunctive rules.
Used in KBANN (Knowledge-Based ANN) networks, where symbolic knowledge is used to specify initial weights.
IF(M of N antecedents (A1, A2 ... AN ) are true) THEN ...
Newer work: M of N3 algorithm:
R. Setiono, "Extracting M of N Rules from Trained Neural Networks", Transactions on Neural Networks 11 (2000) 512-519
Penalty term to prune the network, inputs should be binary.
M. W. Craven, J.W. Shavlik, "Using sampling and queries to extract rules from trained neural networks". In: Proc. of the Eleventh Int. Conference on Machine Learning, New Brunswick, NJ. Morgan Kaufmann 1994, pp. 37-45
Rule extraction = learning logical function that approximates the target (neural network) function.
Rules: IF ... THEN ... ELSE, M-of-N
S. Thrun, "Extracting rules from artifcial neural networks with distributed representations". In: G. Tesauro, D. Touretzky, T. Leen, eds, Advances in Neural Information Processing Systems 7. MIT Press, Cambridge, MA, 1995
Extract rules mapping inputs directly to the outputs, try to capture what does the network do, global method.
Rules: IF ... THEN ... ELSE
Numerous rules, too specific. Has not been used much?
E. Pop, R. Hayward, J. Diederich,
"RULENEG: extracting rules from a trained ANN by stepwise negation",
QUT NRC technical report, December 1994;
R. Hayward, C. Ho-Stuart, J. Diederich and E. Pop, "RULENEG: extracting rules from a trained ANN by stepwise negation", QUT NRC technical report, January 1996
Forms conjunctive rules, one per input pattern.
For input pattern that is not correctly classified by the existing set of rules:
For i =1..N
Determine class of (x1, ... NOT.xi, ... xN)
If the class has changed add R = R.AND.xi
S. Sestito, T. Dillon, "Automated knowledge acquisition". Prentice Hall (Australia), 1994
Network of M inputs and N outputs is changed to a network of M+N inputs and N outputs and retrained.
Original inputs that have weights which change little correspond to the most important features.
A.B. Tickle, M. Orlowski, J. Diederich, "DEDEC: decision detection by rule extraction from neural networks", QUT NRC technical report, September 1994
Rule extraction: find minimal information distinguishing a given pattern from others from the NN point of view.
Rank the inputs in order of importance - determine the importance of input features, using input weights.
Select clusters of cases with important features (using k-NN ) and use only those features to derive rules.
Learn rules using symbolic induction algorithm.
R. Andrews, S. Geva, "Rule extraction from a constrained error back propagation MLP". Proc. 5th Australian Conference on Neural Networks, Brisbane, Queensland 1994, pp. 9-12
Special MLP network, using local response units - combination of sigmoids in one dimension, forming ridges.
Disjoint regions of the data <--> one hidden unit.
Similar to symmetric trapezoid neurofuzzy approach.
Trained with Constrained Backpropagation (some weights are kept fixed).
Inserting and refining rules is possible.
Propositional Rules:
IF Ridge1 is active and Ridge2 is active and .... THEN Classk
Works for continuos & discrete inputs.
M. W. Craven, J.W. Shavlik, "Extracting tree-structured representations of trained networks". In: D. Touretzky, M. Mozer, M. Hasselmo, eds, Advances in NIPS 8, MIT Press, Cambridge, MA 1996.
Decision tree instead of rules - inductive algorithm.
NN treated as “oracle” answering queries.
Queries may be incomplete patterns.
Oracle determines class labels, is used to selects splits of nodes and to check if a tree node covers a single class only.
Tree expansion: best-first method, with node splits representing binary and M-of-N rules.
Spilt: partition input space to increase separation of input patterns into classes.
Nodes evaluated by: % cases reaching it times the % of errors in the node.
Split selected only after >1000 cases considered.
Thanks to oracle - works better than other inductive algorithms.
Conclusion: if a black box classifier works well on your data and rule-based description is required - use it as oracle!
M. Ishikawa, "Rule extraction by succesive regularization". In: Proc. of 1996 IEEE Int. Conf. on Neural Networks. Washington, 1996, pp. 1139-1143.
Structural learning with forgetting (SLF):
MLP with Laplace-type regularizing term:
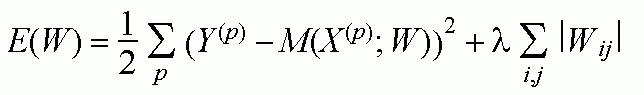
(X(p), Y(p)) - question-response patterns p;
Wij - connection weight between units i and j.
Selective forgetting: only weights smaller than some threshold are included in the regularizing term.
This term leads to a constant decay of smaller weights.
Small weights are pruned and a skeletal network emerges.
Clarification of hidden units: 0/1 outputs forced by penalty term
c Si min (1-hi,hi)
Successive regularization:
Start from rather large l, get dominant rules first.
Fix the parameters of this part of the network.
Decrease l, train network => more connections left, more rules.
Skeletal structure + 0/1 outputs of hidden units => each node is represented as a logical function of nodes in the adjacent lower layer.
Good method but requires many experiments to find good initial network.
P. Geczy and S. Usui, "Rule extraction from trained neural networks". Int. Conf. on Neural Information Processing, New Zealand, Nov.1997, Vol. 2, pp. 835-838
Train the network.
Replace resulting weights by resulting 0, +1 and -1
Extract logical functions performed by the network.
Approximation of MLPs by by Boole'an functions.
Network function is approximated by lower order logical polynomials.
Results are not too good.
General remarks:
Decision Trees (DT) are simple to use, use a few parameters, provide simple rules.
Most DT are univariate, axis-parallel.
Oblique trees use linear combinations of input features.
D - training set partitioned into Dk subsets by some tests T.
Stop(Dk)=True if assumed leaf purity is reached.
Trees are pruned to improve generalization and to generate simpler rules.
Breiman, L., Friedman, J., Olshen, R., and Stone, C. (1984) Classification and Regression Trees", Wadsworth.
Split criterion is based on Gini(node) index:
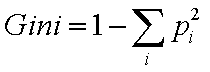
pi is the probability of class i vectors in the node.
For each possible split calculate Gini, select split with minimum impurity.
Use minimal cost-complexity pruning, rather sophisticated.
DB-CART - added boosting and bagging.
Boosting: making a committee of many classifiers trained on the same training data, with re-weighted wrongly classified cases.
Bagging, bootstrap aggregating: making a committee of many classifiers trained on subsets of data created from the training set by bootstrap sampling (i.e. drawing samples with replacement).
Commercial version of CART and IndCART: different ways of handling missing values and pruning.
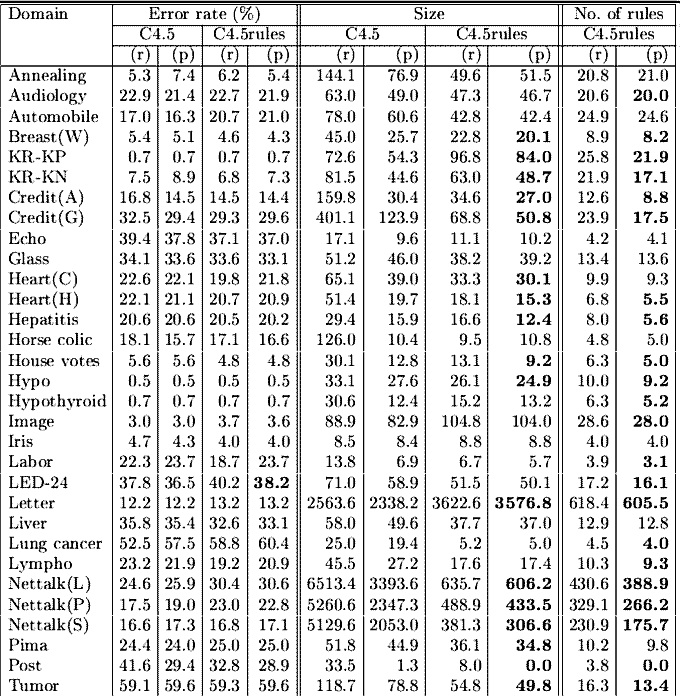
Quinlan, J. R. (1993). C4.5: Programs for Machine Learning. San Mateo: Morgan Kaufmann.
C 4.5 splitting criterion is the gain ratio:
for C classes and fraction p(D;j)=p(Cj|D) in j-th class
the number of information bits the set D contains is:
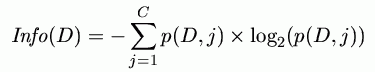
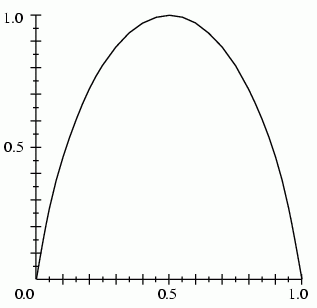
For 2 classes information (vertical) changes with p(D;1)=1-p(D;2) reaching max. for 0.5
Info = expected number of bits required to encode a randomly selected training case.
Information gained by a test T with k possible values is:
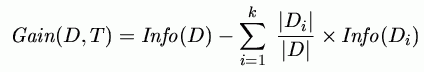
Max. for tests separating D into one-dimensional subsets; attributes with many values are always selected.
Use information gain ratio instead: gain divided by the split information
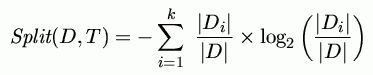
Improvements of continuous attribute treatment in C5:
C4.5 rule generation algorthm, used usually before pruning.
Convert each tree path to a rule:
IF Cond1 AND Cond2 ... AND Condn THEN class C
Z. Zheng, "Scaling Up the Rule Generation of C4.5". Proc. of PAKDD'98, Berlin: Springer Verlag, 348-359, 1998.
Rules are frequently more accurate and simpler than trees, especially if generated from pruned trees.
G.P. J. Schmitz, C. Aldrich, and F.S. Gouws, "ANN-DT: An Algorithm for Extraction of Decision Trees from Artificial Neural Networks". Transactions on Neural Networks 10 (1999) 1392-1401
Train an MLP or RBF model
Generate more data interpolating input points in the neighborhood of the training data (equivalent to adding noise).
Use NN as an oracle to predict class.
Create DT using CART criteria or alternative criteria (correlation between variation of the network and variation of the attribute) to analyze attribute significance.
Prune the network using CART approach.
A few results so far, first good NN should be created.
Many variants of the oblique tree classifiers: CART-LC, CART-AP, OC-1, OC!LP, OC-1AP ...
For some data results are significantly better, trees are smaller, but rules are less comprehensible - combinations of inputs are used.
There is no comparison between neural methods of rule extraction (with aggregation) and oblique trees so far.
R. Michalski, "A theory and methodology of inductive learning". Artificial Intelligence 20 (1983) 111-161.
StatLog project book:
D. Michie, D.J. Spiegelhalter and C.C. Taylor,
"Machine learning, neural and statistical classification".
Elis Horwood, London 1994
Many inductive methods have been proposed in machine learning.
S. Weiss, 1988
Maximize predictive accuracy of a single condition rule, make exhaustive or heuristic search.
Try combinations of 2 conditions.
Expensive but for small datasets finds very simple rules.
Exemplars are maximally specific rules.
Use hybrid similarity function, good for nominal and numerical attributes.
{kind=link}