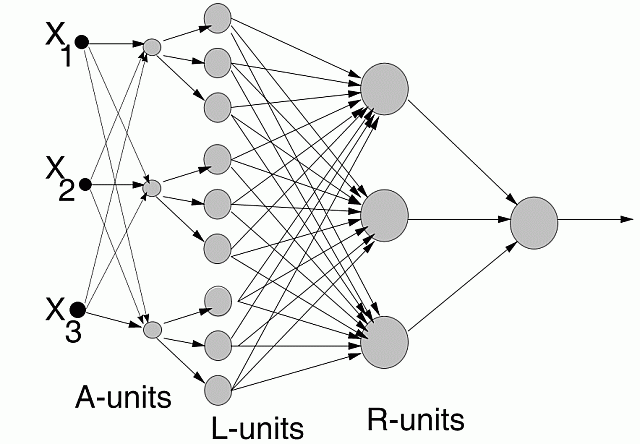
Architecture:
Aggregation: used to combine and discover new useful features.
Used only if rules with the given features are not successful.
Constraints: combinations of features of the same type, combinations making sense.
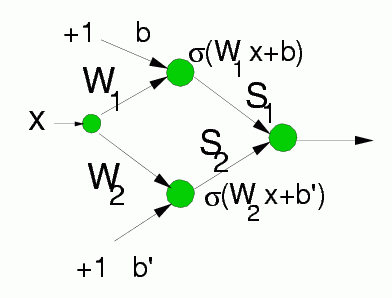
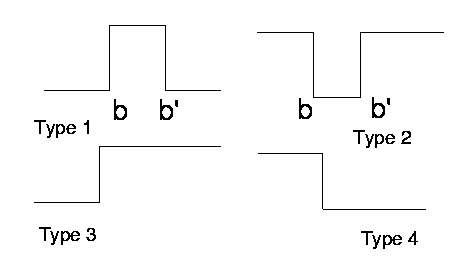
L-units: providing intervals for fuzzy or crisp membership functions
Made from 2 neurons, only biases are adaptive parameters here.
Without L-units decision borders will be arbitrary hyperplanes made by combinations of inputs - sometimes it may be advantageous.
Used only with continuous inputs; if good discretization provided may not be necessary.
Great to optimize linguistic variables together with the rules.
Constraint MLP cost function
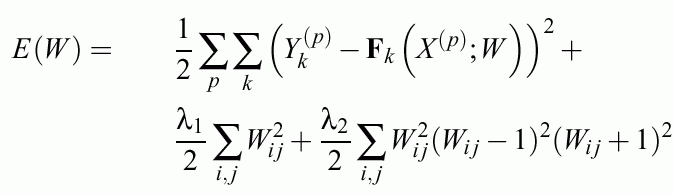
First term: standard quadratic error function (or other cost functions)
Second regularization term: weight decay & feature selection.
Third regularization term: from complex to simple hypercuboidal classification decision regions for crisp logic (for steep sigmoids).
Different regularizers may be used but there is not much difference in practice.
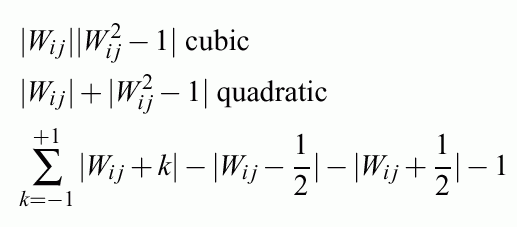
Different error functions may be used: quadratic, entropy based etc.
Very simple modification of the standard BP required
Increase the slope of sigmoidal functions during learning to get rectangular decision borders.
Another approach: increase a in the regularization term:
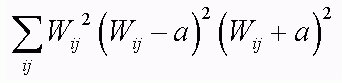
This prunes the network leaving large weights, which is equivalent to increasing the slope.
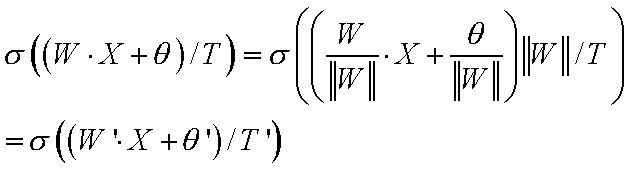
Without logical inputs this allows large but non-equal weights.
What makes the decision borders perpendicular to axis?
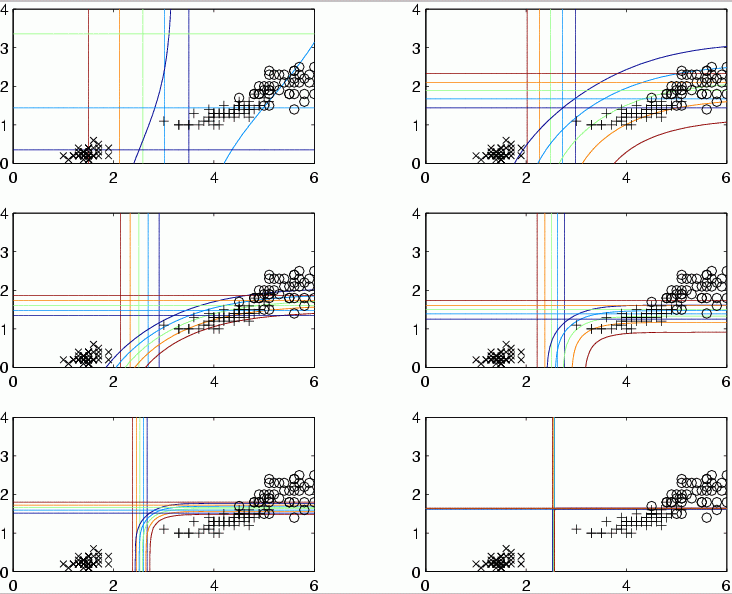
Logical rules from MLP: simplify the network by enforcing weight decay and other constraints.
Strong and weak regularization allows to explore simplicity-accuracy tradeoff.
Algorithm:
Many equivalent sets of rules may be found.
Non-gradient optimization methods - closer to global optimum, better rules?
So far poor results but more experiments are needed - use Alopex?
Summary