Kompresja obrazów cyfrowych
Kompresja danych — zmiana sposobu kodowania informacji cyfrowej, dzięki której zapis "typowych" danych ulega znacznemu skróceniu. Celem kompresji jest oszczędność obszaru pamięci przy przechowywaniu i/lub czasu przy transmisji danych.
Twierdzenie: Nie istnieje metoda kompresji, który skracałaby wszystkie możliwe pliki o początkowej długości n bitów.
Dowód: Nie istnieje różnowartościowe odwzorowanie zbioru 2n elementowego w zbiór 2n-1 lub mniej elementowy.
Innymi słowy: każdy algorytm kompresji bez strat jest z konieczności nieefektywny na pewnych typach danych, generując pliki dłuższe niż wyjściowe. Reklamowane często w Internecie "cudowne" algorytmy kompresji, redukujące rzekomo rozmiar wszelkich możliwych danych to bzdura.
Niektóre formaty skompresowanych plików graficznych
Algorytm Huffmanna (1952)
Algorytm wykorzystuje różnice w częstości występowania poszczególnych znaków w tekście (bajtów w pliku): najczęściej występujące znaki otrzymują najkrótsze kody binarne, zaś najrzadsze — najdłuższe kody. W skompresowanym pliku pamiętana jest też tabelka–słownik, pozwalająca odtworzyć w dekompresji prawdziwą postać znaków (bajtów).
Algorytm Huffmana konstruuje drzewo binarne, łącząc ze sobą dwa drzewa o najmniejszych wagach (częstościach) spośród drzew uzyskanych w poprzednich krokach. Tak utworzonemu drzewu nadaje się wagę równą sumie wag łączonych drzew. Na początku każdemu ze znaków występujących w tekście odpowiada drzewo o dwóch węzłach — jeden reprezentujący znak i drugi określający jego wagę, czyli częstość pojawiania się w tekście.
Przykład
Tekst o długości 57 znaków zawiera litery a, b, c, d, e, f, g. Do rozróżnienia 7 znaków wystarczą kody 3-bitowe, 001, 010, 011, ..., 111. Stąd "oszczędna" reprezentacja tego tekstu liczy 57*3 = 171 bitów. Jednak znaki różnią się częstością występowania w tekście.
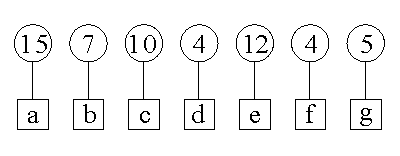
Krok 1: wybieramy "d" i "f" jako najrzadziej występujące i łączymy je w drzewo o wadze 4+4=8.
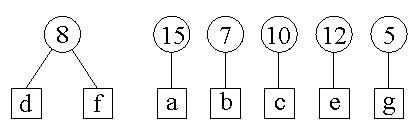
Krok 2: dwie najmniejsze wagi to 5 i 7, litery "g" i "b" — łączymy je w drzewo.
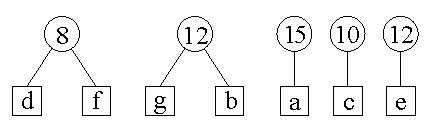
Krok 3
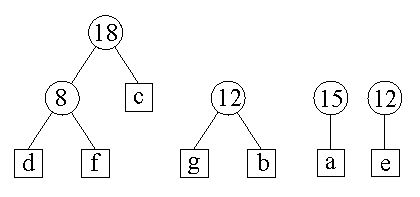
Krok 4
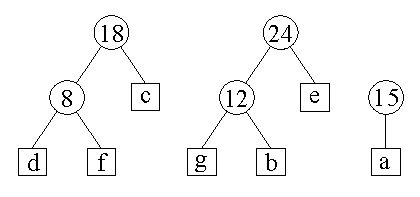
Krok 5
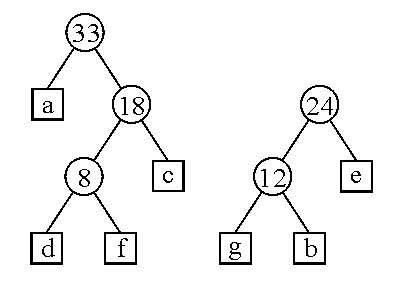
Krok 6
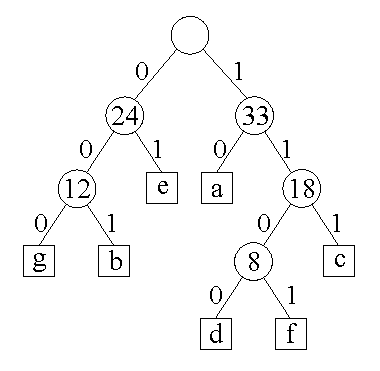
Nowe kody znaków odczytuje się z utworzonego drzewa: w lewo — 0, w prawo — 1. W ten sposób mamy:
| a | b | c | d | e | f | g |
| 10 | 001 | 111 | 1100 | 01 | 1101 | 000 |
Oszczędność bierze się z zastosowania krótkich 2-bitowych kodów dla najczęściej występujących znaków:
15*2 + 7*3 + 10*3 + 4*4 + 12*2 + 4*4 + 5*3 = 152 < 171 bitów.
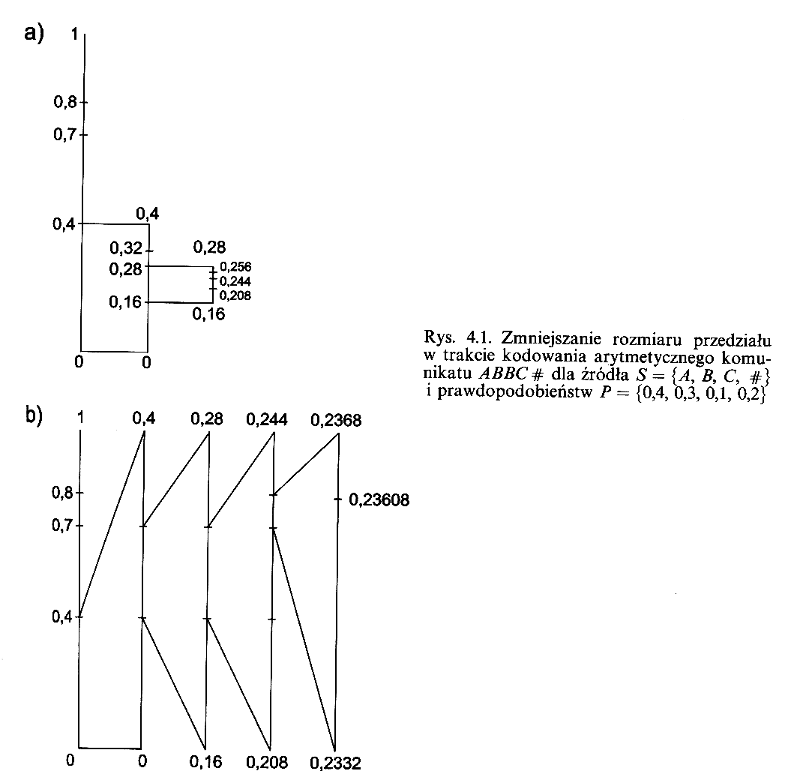
Kodowanie arytmetyczne oparte jest podobnie jak kodowanie Huffmanna na zmiennej częstości występowania znaków w kompresowanym tekscie