|
|
 |

Goal of Computational Intelligence: not only prediction, diagnosis, classification, but also understanding of the data, explanation, reliability assesment, knowledge discovery, building theories and causal models.

What type of explanation is satisfactory?
Interesting cognitive psychology (CS) problem.
Exemplar and prototype theories of categorization in CS.
Types of explanation:
"Best explanation" - depends on particular field.
Logical rules, if simple enough, are preferred by humans.

Rules require symbols, defined by predicate functions Property(X)Î [0,1].
Perception:
Types of logical rules:
Crisp logic rules:
for continuos X use linguistic variables Property(X) = 0 or 1 (F/T):
IF small-height(X) AND has-hat(X) AND has-beard(X) THEN (X is a Brownie)

ELSE IF ... ELSE ...
Crisp logic based on rectangular membership functions: True/False values jump from 0 to 1.
Step functions are used for partitioning of the input space.
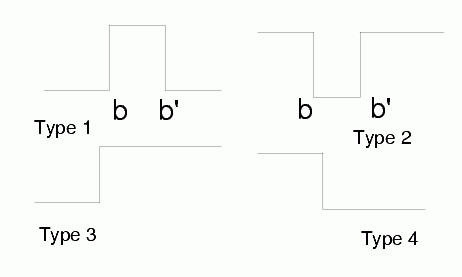
Decision regions: hyperrectangular (cuboidal).
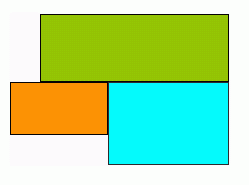
The number of problems that one may analyze using crisp logic may be limited.
Crisp logic rules are most desirable; try them first,
but remember ...

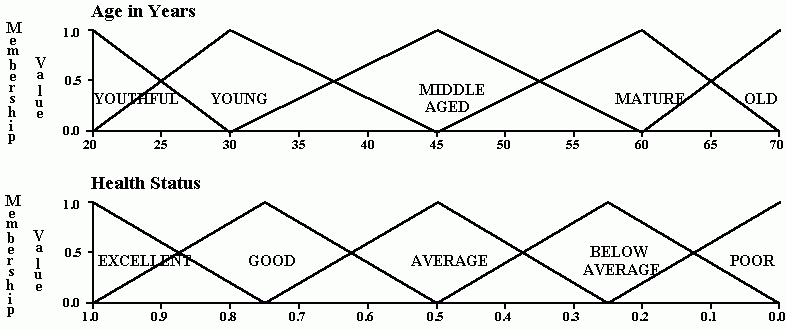
Fuzzy logic rules
Property(X)Î [0,1] instead of 0 or 1.
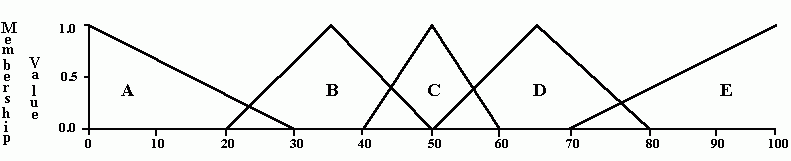
Typical approach: define triangular, trapezoidal, Gaussian and other type of predicate (membership) function.
Membership function m(X) - degree of truth that X has the property m
Frequently features are partitioned by membership functions, defining large receptive fields, reducing information (?).
For example, using triangular functions.
Fuzzy logic: separable functions - products of one-dimensional factors:
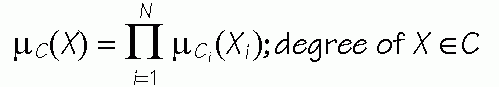
Many other possibilities exist to produce N-dimensional membership functions.
Fuzzy rules have continuous membership functions, giving some advantages:
But remember ...
 danger of overparameterization - more complex rules have additional position/shape parameters.
danger of overparameterization - more complex rules have additional position/shape parameters.
Example: Ljubliana breast cancer
286 cases, 201 no recurrence cancer events (70.3%), 85 are recurrence (29.7%) events.
9 features, symbolic with 2 to 13 values.
Single logical rule:
IF involved nodes >2 AND Degree-malignant=3 THEN recurrence
ELSE norecurrence
gives over 77% accuracy in crossvalidation tests;
best classification systems do not exceed 78% accuracy (insignificant difference).
Some fuzzy/rough systems provided 200 rules with CV accuracy close to the base rate!
Reason: too complex, hard to find simplest solution.
All knowledge contained in the data is:
IF more than 2 areas were infected
AND cancer is highly malignant
THEN there will be recurrence.

Context-dependent linguistic variables - adapt membership functions in each rule.
Effect: clusters of different sizes at different input areas.
|
Clusters may have complex decision border shapes. IF XÍC THEN Factk = TRUE Simple rules - non-linear feature transformations may be required.
|
|
Problems with rule-based classification models:
Simplest things first: try crisp rules, large information reduction.
Data from measurements/observations are not precise.
Finite resolution, small receptive fields: Gaussian error distribution:
x => Gx=G(y;x,sx), where Gx is a Gaussian (fuzzy) number.
Given a set of logical rules {Â} apply them to input data {Gx }.
Use Monte Carlo sampling to recover p(Ci | Gx; {Â
}) - may be used with any classifier.
The rule Ra(Gx) = True{x|x>a} is true with probability:
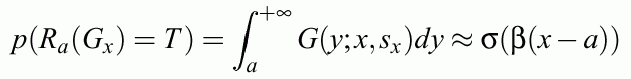
because the cumulant function is approximated by the logistic function:
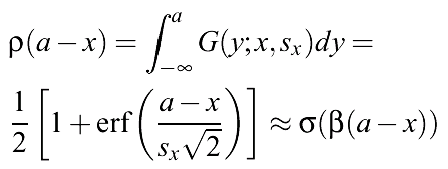
for 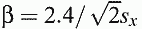 within 2%
within 2%
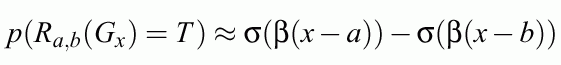
Soft trapezoidal membership functions (MF) realized by neural L-units are obtained.
Fuzzy logic with soft trapezoidal MF and crisp inputs is equivalent to crisp logic with Gx inputs;
MLP neural networks with logistic transfer functions provide such MFs.
MLP model includes FL with trapezoidal membership functions.
If rules are overlapping and conditions are correlated the formula leading to Monte Carlo results is:
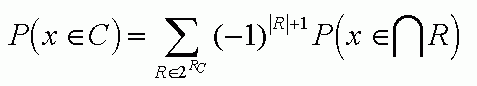
where 2Rc are all subsets of the set of classification rules for class C and |R| is the number of rules.
This formula simply avoids counting the same regions twice.
This is not a fuzzy approach!
Here small receptive fields are used, in fuzzy approach a few large receptive fields define linguistic variables.
Benefits:
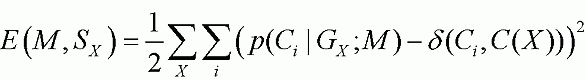
Next step: optimization of rules exploring the confidence-rejection rate tradeoff.
Define confusion matrix F(Ci,Cj|M) counting the number of cases from class Cj assigned by the set of rules M to the class Ci.
For 2 class problems:
| F(Ci,Cj|M) = |
|
where Fij is the frequency of cases Nij / N.
F(Ci,Cj |R) may be defined for a rule or a (sub)set of rules.
Ideal: only the diagonal confusion matrix elements summing to N should be left.
Define weighted combination of the number of errors and the "predictive power" of rules:
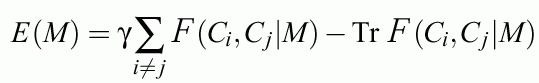
This should be minimized without constraints; it is bound by -N (number of all training vectors).
Sets of rules M are parameterized by Xk, X'k intervals.
For g=0 predictive power of rules is maximized.
Rules that make fewer errors on the training data should be more reliable.
Cost function E(M; g) allows to reduce the number of errors to zero (large g) for rules M that reject some instances.
How to understand the data?

Explanatory data analysis - show the data.
Kohonen's topographics SOM - most popular, trying to classify/display at the same time, but poor in both respects.
Assesing the new data:
Investigate the dependence of p(C|GX; M,S) on S.
If new classes with significant probability appear analyse dependence of
p(C|GX; M,S) on S on individual features Xi.
Example:
with Si =0 "organic problems'' with 100% confidence;
with 1% uncertainty (optimal, lowest error) "organic problems'' with 90% confidence.
Probabilities of different classes are shown as a function of assumed uncertainties.
Si=r [Maxi- Mini], horizontal axis shows r in percents of the input feature range, vertical axis shows probability in percents.
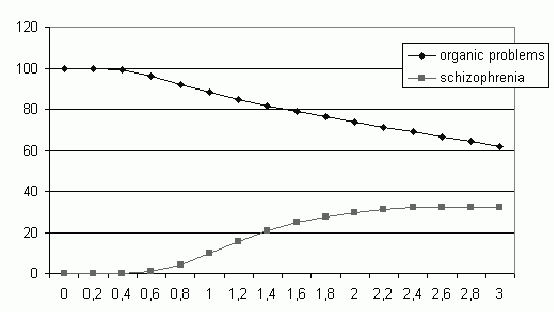
In ambiguous cases probabilities of several new classes quickly rise for growing r and of the most probable class quickly decrease.
PCI, Probabilistic Confidence Intervals
If probability of new classes quickly grows with the assumed uncertainty of the measurement analyze
probabilistic confidence levels.
Assume that the value of a single feature is changed, all other are constant; display the two largest probabilities.
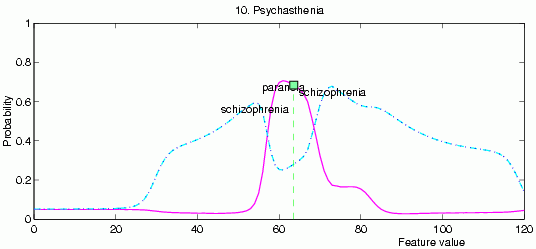
A mixed class appears: paranoidal schizophrenia.
Sensitivity analysis: which feature has strongest influence on the decision?
Shows probabilities in the neighborhood of the case analyzed for a single feature.
Allows to evaluate reliability of classification, but not to explain the data.
May be used with any classifier.
May illustrate the trajectory of changes:
IMDS, Interactive MultiDimensional Scaling
Shows interactively the neighborhood of the case analyzed trying to preserve all topographic relations.
Minimization of a Stress function as:
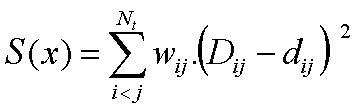
where wij are weights allowing to control which distances are to be better preserved.
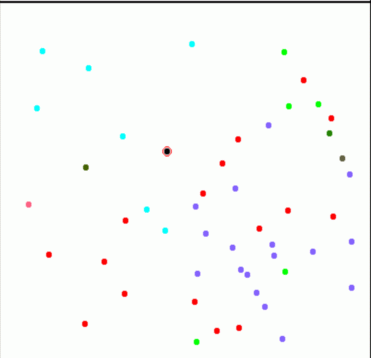
Example: focusing on a data point 'p554' from class 'organika'
- Purpose: view (understand) why this data is classified into class 'organika'.
Classified using IncNet neural network, for which features 2, 4 and 7 are sufficient to classify correctly class 'organika'.
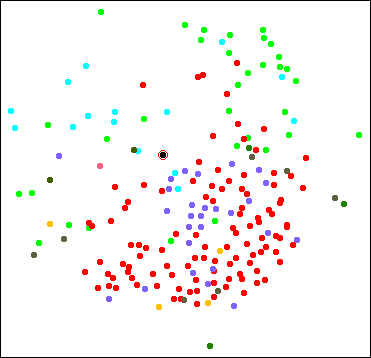
Progressive zooming by mapping successively the 200, 100, 50 and 20 nearest data points (interactively selected) from point 'p554' (marked by a black circled dot).
|
200 nearest neighbors |
50 nearest neighbors |
|
|
|
An example of a system based on rules derived from data.
An example of data where logical rules do not work.
871 patterns, 6 overlapping vowels, 3 features (formant frequencies).
No reason why simple rules should exist in this case.
| Method | | Reference |
| 10xCV tests below | ||
| 3-NN, Manhattan | 88.1 ±0.4 | Kosice |
| FSM, 65 Gaussian nodes | 87.4 ±0.5 | Kosice |
| SSV dec. tree, 22 rules | 86.0 | Kosice |
| 2xCV tests below | ||
| 3-NN, Euclidean | 86.1 ±0.6 | Kosice |
| FSM, 40 Gaussian nodes | 85.2 ±1.2 | Kosice |
| MLP | 84.6 | Pal |
| Fuzzy MLP | 84.2 | Pal |
| SSV dec. tree, beam search | 83.3 ± 0.9 | Kosice |
| Bayes Classifier | 79.2 | Pal |
| Fuzzy SOM | 73.5 | Pal |
More than 20 rules give lower accuracy than kNN.
Simplest explanation: 6 FSM prototypes (one per class), Gaussian weighting of the Euclidean distance.
10xCV gives 72.4% accuracy - insufficient info in the 3 formants.
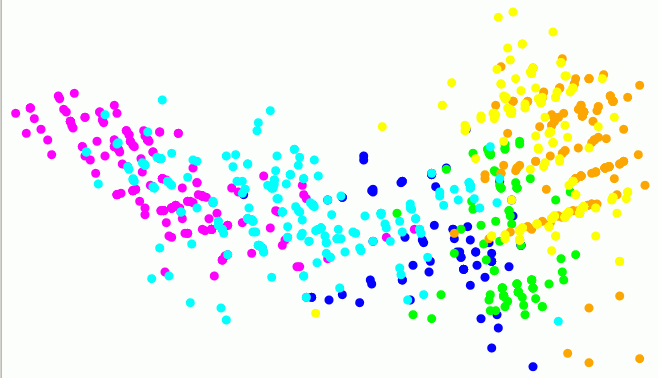
Understanding the data is possible through:
Rules: frequently rule sets are unstable and/or rule-based classification is unstable.
Small number of accurate rules - best explanation?
Interpretation/evaluation of new cases:
Class probabilities may always be estimated by Monte Carlo.
For crisp and most fuzzy rule sets analytical formulas exist.
Most papers are available from these pages
https://is.umk.pl/~duch/index.html
https://is.umk.pl/~duch/cv/papall.html